
תוך 3 שניות בלבד, AI שמעולם לא שמע אותך מדבר יכול לחקות את הקול שלך בצורה מושלמת. זהו ההישג האחרון של הבינה המלאכותית של מיקרוסופט - מודל הטקסט-לדיבור VALL-E, שיכול להעתיק קולו של כל אחד כרצונו ב-3 שניות דיבור בלבד.
Microsoft VALL-E תחקה את הקול שלנו לאחר 3 שניות בלבד של דיבור
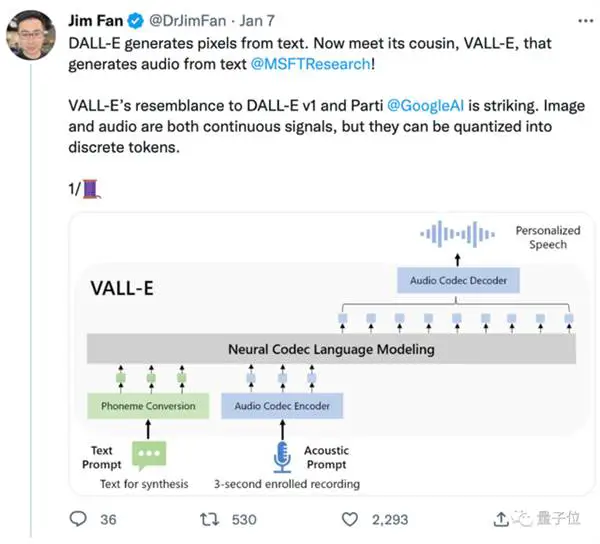
מקורו ב-DALL E, אך מתמחה בתחום האודיו, ואפקט הטקסט לדיבור הפך לפופולרי לאחר יציאתו לרשת.
חלק מהמשתמשים אמרו שאם VALL·E ו-ChatGPT משולבים, התוצאה תהיה מדהימה. לאחרים נראה שהיום שבו ניתן יהיה לבצע שיחות וידאו עם AI לא רחוק. יש אפילו כאלה שמתבדחים שאחרי שה-AI טיפל בסופרים ובציירים, הבאים הם השחקנים.

אבל איך VALL·E מחקה צליל "לא נשמע" תוך 3 שניות?
VALL-E מנתח אודיו עם מודלים של שפה. הוא מסנתז דיבור על בסיס צלילים "לא נשמעים" של בינה מלאכותית, כלומר למידה של אפס מדגם.
הפתרון המסורתי של טקסט לדיבור הוא בעצם מצב טרום אימון יחד עם כוונון עדין. אם נעשה שימוש בתרחיש מדגם אפס, זה יביא לדמיון וטבעיות לקויים של הדיבור שנוצר.

בהתבסס על זה, VALL-E הגיע משום מקום, והציע רעיון שונה מהמודל הקולי המסורתי.
בהשוואה למודל המסורתי המשתמש בספקטרום Mel כדי לחלץ תכונות, VALL-E לוקח ישירות את סינתזת הדיבור כמשימה של מודל השפה, הראשון הוא רציף והשני הוא דיסקרטי.
בפרט, תהליך סינתזת הדיבור המסורתי הוא לעתים קרובות הנתיב של "פונמה → מל-ספקטרוגרם (מל-ספקטרוגרם) → צורת גל".
אבל VALL -E הפך את התהליך הזה ל"פונמה → קידוד אודיו בדיד → צורת גל":
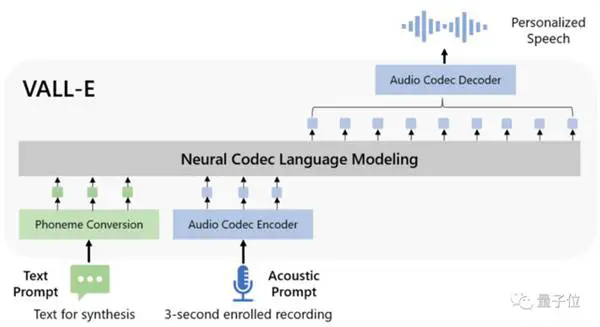
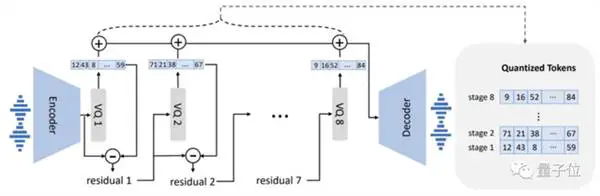
מבחינת עיצוב הדגם, VALL-E דומה גם ל-VQVAE. מכמת אודיו לסדרה של אסימונים נפרדים. הקוואנטייזר הראשון אחראי ללכידת תוכן האודיו ומאפייני הזהות של הרמקול, בעוד שהקוונטיזרים השני אחראים על חידוד האות. מה שנשמע יותר טבעי:
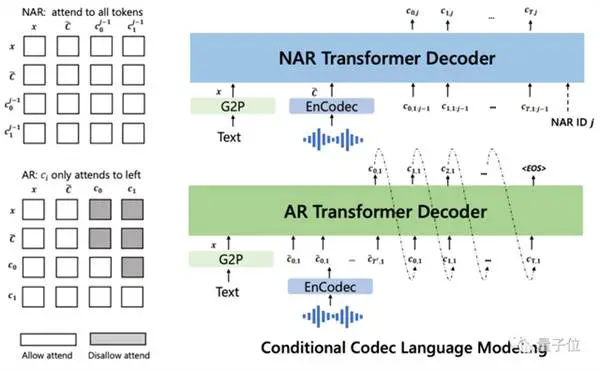
לאחר מכן מותנה על ידי הטקסט והנחיית השמע של 3 שניות, הוא מוציא באופן אוטומטי קידוד אודיו בדיד:
אבל לא רק זה, בנוסף לסינתזת דיבור עם דגימה אפסית, VALL-E תומך גם בעריכה קולית ויצירת תוכן קולי בשילוב עם GPT-3.
ניתן גם לשחזר את צליל הרקע הסביבתי
אם לשפוט לפי האפקטים הווקאליים המסונתזים, VALL-E יכול לשחזר יותר מסתם הגוון של הרמקול.
לא רק שמחקים את הגובה במקום, אלא שהוא גם תומך במגוון מהירויות דיבור שונות. לדוגמה, אלו הן שתי מהירויות דיבור שונות המסופקות על ידי VALL-E כאשר אותו משפט נאמר פעמיים, אך הדמיון הטונאלי עדיין גבוה:
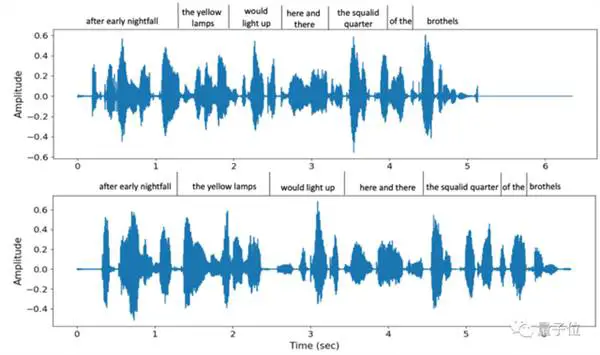
במקביל, ניתן לשחזר במדויק גם את צליל הסביבה הרקע של הצד השני.
בנוסף, VALL-E יכול לחקות מגוון רגשות של הדובר, כולל מספר סוגים כמו כעס, ישנוני, ניטרלי, שמחה ובחילה.
ראוי להזכיר שמערך הנתונים המשמש לאימון VALL·E אינו גדול במיוחד.
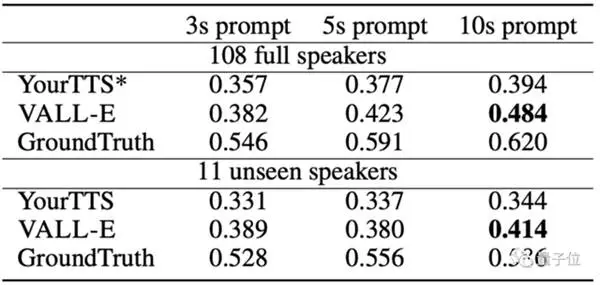
לעומת Whisper של OpenAI, שדרש 680.000 שעות אימון שמע והשתמש רק ביותר מ-7.000 רמקולים ו-60.000 שעות אימון, VALL-E עלה על טקסט לדיבור שהוכשר מראש מבחינת הדמיון לדגם YourTTS טקסט לדיבור.
בנוסף, YourTTS שמעה את הקולות של 97 מתוך 108 רמקולים מראש במהלך האימון, אך הוא עדיין נופל מ-VALL-E במבחן בפועל.
לגבי השדות שבהם ניתן ליישם את זה:
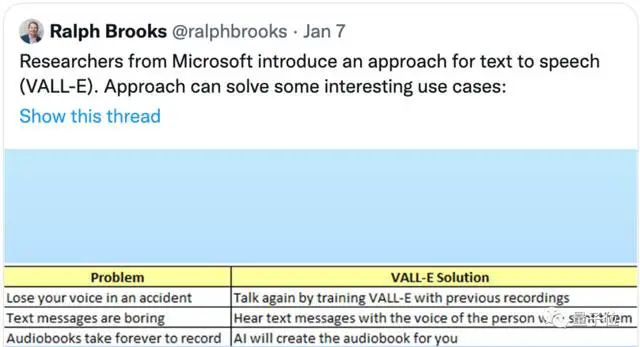
לא רק שניתן להשתמש בו כדי לחקות את הקול שלך, כגון לעזור לאנשים עם מוגבלויות להשלים שיחה עם אחרים, אלא שאתה יכול גם להשתמש בו כדי לדבר במקומך כשאתה לא רוצה. כמובן, ניתן להשתמש בו גם להקלטת ספרי אודיו.
עם זאת, VALL-E אינו עדיין קוד פתוח וייתכן שתצטרך לחכות עוד קצת כדי לנסות אותו.






